Ilze Amanda Auzina
contact me:
ilze.auzina@bethgelab.org
About me
I am an ELLIS PhD researcher in Machine Learning working with Prof. Dr. Matthias Bethge at Tübingen University, Germany. Previously, I worked with Dr. Efstratios Gavves and Dr. Sara Magliacane at University of Amsterdam in Video & Image Sense Lab.
Before starting my PhD I collaborated with Dr. Jakub M. Tomczak on my Master Thesis at Vrije Universiteit, Amsterdam on Approximate Bayesian Computation for discrete data, which was nominated for best Master Thesis award.
Currently, my research is driven by a central question:
How can we successfully extend RL post-training beyond math and coding tasks to open-ended problems?
Research Focus
Early PhD: ML for Science
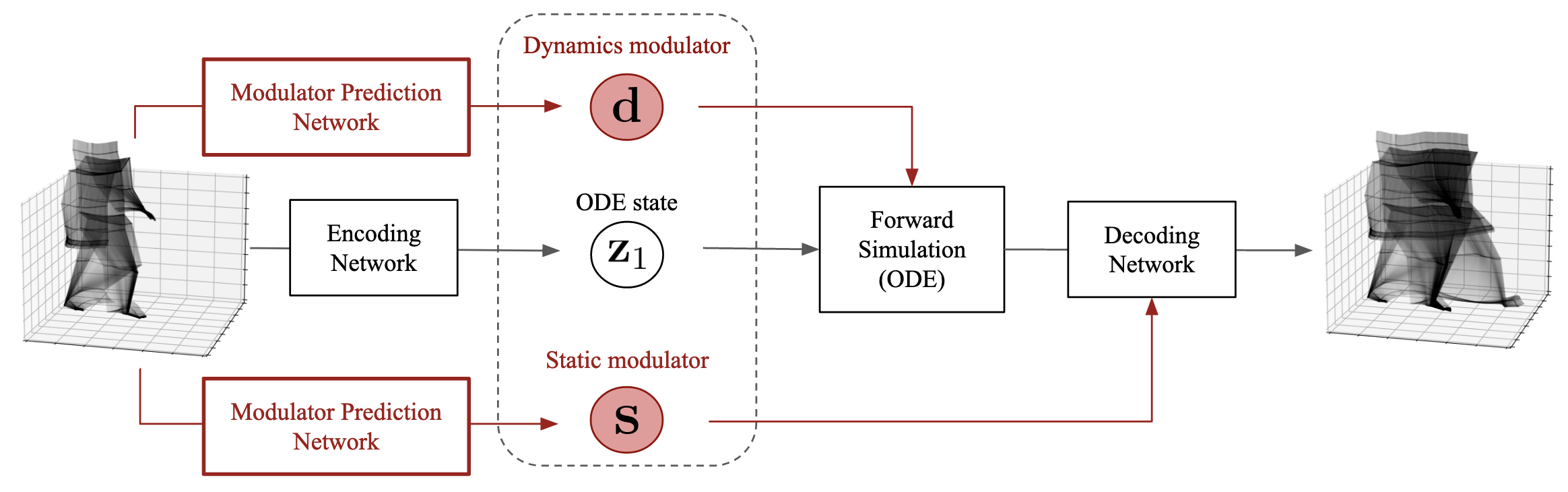
In the early stages of my PhD, I explored machine learning for scientific modeling, particularly dynamical systems. I focused on teaching neural networks to infer latent dynamics from high-dimensional data while enforcing appropriate structural or physical constraints.
This included work on:
- Neural ODEs and GP-ODEs combined with VAE-based latent dynamics
- Modulated dynamics with explicit parameter control
- Ensuring learned systems reflect true physical structure rather than overfitting observations
Current: RL Post-Training for LM
Given the pivotal moment of DeepSeek-R1, my research focus shifted towards LM RL post-training. LM agents are becoming a crucial component of our daily lives, I want to be on the edge of science that helps to understand their capabilities and improve them for our daily lifes:
I currently work on:
- Dense reward modeling and objective shaping (e.g. intrinsic incentive guided exploration)
- Stability in RLVR pipelines
- Open-ended and multi-step environments where reward sparsity poses major training problem
What Drives Me
I enjoy research that combines:
- Real-world impact: Inference with large LMs is expensive, can we obtain the same reasoning abilities via smaller models with RL or on policy distillation.
- Practical design: I value methods that are simple, robust, and usable. Research that others can build on, deploy, or learn from without unnecessary complexity.
- Deep understanding: Is RL genuinely enabling novel reasoning abilities, or is it primarily sharpening what supervised training already provides? Answering questions like these helps us design better, more grounded learning systems.
Ultimately, I aim to work on problems at the frontier — areas that matter but are often overlooked or underexplored in mainstream industry research. If our research interests intersect, feel free to reach out. I’m always happy to connect, collaborate, and discuss ideas.